
Sentiment Analysis on Joe Rogan’s Youtube Comments
 Photo by Shubham Dhage on Unsplash
Photo by Shubham Dhage on Unsplash
What is Sentiment Analysis?
Sentiment Analysis (SA) refers to the use of Natural Language Processing (NLP) to systematically identify, extract, quantify, and study affective states and subjective information.
Sentiment analysis would use different techniques to tokenize and analyze every word and sentence and gather as many signals to indicate whether a text is positive, negative, or neutral. But in order to do that, we have to collect as much raw data as possible and train a model to extract a list of features from a predefined set of positive, neutral and negative responses.
Sentiment analysis is also one of the main use cases for NLP. It allows data scientists to assess comments posted on social media to see how their company’s brand behaves, for example, or to review ratings from customer service teams to identify areas in which customers want that the company is making improvements.
In this article, we will use comments on the latest Joe Rogan Youtube video and use a state-of-the-art NLP model to predict the basic sentiment on each and every comment, and finally look at the overall sentiment distribution of the video comments.
Find and collect the Data
To collect the data we will use an unofficial Youtube API to get all the comments, in order to do that we need to follow this steps:
- Create a RapidAPI account
- Subscribe to the Youtube API
- Start collection the data 🚀
![]()
When you go to the API’s page you will find a list of endpoints, for the purpose of this tutorial we are interested in two endpoints:
- /video/comments/ : this endpoint will give the fist 20 comments and more importantly a token to continue to the next page of comments, this endpoint needs one argument:
- video_id (string)
- /video/comments/continuation/ : this endpoint will give us the next 20 comments and the continuation token to perform the next request, this endpoint takes two arguments:
- video_id (string)
- continuation_token (string)
Create a mapping Python Class
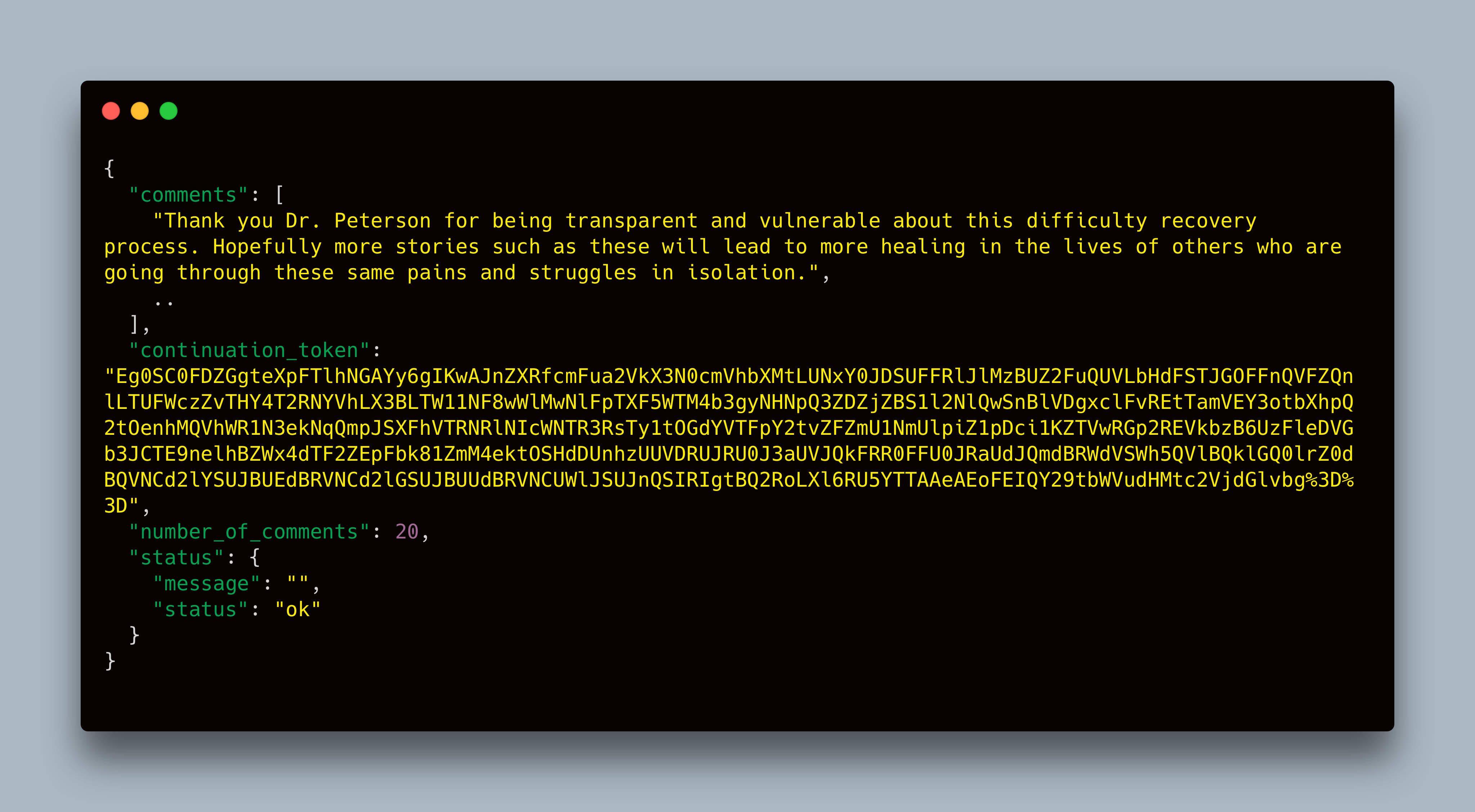
To make our life easy, we can take advantage of Python Dataclasses to create a direct mapping of the API response
@dataclass(init=True, repr=True)
class Comments:
comments: List[str]
continuation_token: str
number_of_comments: int
status: Dict
We can easily map the response using the ** operator.
Here’s an example of the expected data response:
Make the API calls and save the comments
The first call is a GET method and will get us the first 20 comments with the first continuation token:
def simple_call(video_id: str) -> Comments:
url = "https://youtube-search6.p.rapidapi.com/video/comments/"
querystring = {"videoId": video_id}
headers = {
"x-rapidapi-host": "youtube-search6.p.rapidapi.com",
"x-rapidapi-key": RAPID_API_TOKEN,
}
response = requests.request("GET", url, headers=headers, params=querystring)
return Comments(**response.json())
As for the rest of the data we need to make a POST call and use the former call continuation token:
def continuation_call(video_id: str, continuation_token: str) -> Comments:
url = "https://youtube-search6.p.rapidapi.com/video/comments/continuation/"
payload = {"continuationToken": continuation_token, "videoId": video_id}
headers = {
"content-type": "application/json",
"x-rapidapi-host": "youtube-search6.p.rapidapi.com",
"x-rapidapi-key": RAPID_API_TOKEN,
}
response = requests.request("POST", url, data=json.dumps(payload), headers=headers)
return Comments(**response.json())
We can unify the process in a separate function to handle both cases at once:
def get_comments(video_id: str, continuation_token: str = None) -> Comments:
if not continuation_token:
return simple_call(video_id=video_id)
return continuation_call(video_id=video_id, continuation_token=continuation_token)
We can finally collect all the data, for the purpose of this tutorial, I will limit the number of comments to 2500:
list_of_comments = []
comments = get_comments(video_id=VIDEO_ID)
list_of_comments.extend(comments.comments)
while len(list_of_comments) < 2500:
comments = get_comments(
video_id=VIDEO_ID, continuation_token=comments.continuation_token
)
list_of_comments.extend(comments.comments)
print(len(list_of_comments))
with open("comments.json", mode="w", encoding="utf-8") as file:
file.write(json.dumps(list_of_comments))
Predict the sentiments on the comments
To predict the sentiments on the comment, I am using a Transformer based model called roBERTa, which uses an attention mechanism based on how our cerebral cortex works. When we examine a picture to describe it, we naturally focus our attention on a few key places that we know contain crucial information. We don’t examine every detail of the image with the same rigor. As a result, when dealing with complex data, this approach can help save processing resources.
Similarly, when an interpreter translates material from a source language to a target language, they know which terms in a source sentence correspond to a specific term in the translated sentence based on previous experience.
For those interested in a more detailed explanation of Transformer based models, you can read a primer article I wrote a few months back.
Sentiment Analysis iOS Application Using Hugging Face’s Transformers Library
Load the model
TASK = "sentiment"
MODEL = f"cardiffnlp/twitter-roberta-base-{TASK}"
tokenizer = AutoTokenizer.from_pretrained(MODEL)
# download label mapping
labels = []
mapping_link = f"https://raw.githubusercontent.com/cardiffnlp/tweeteval/main/datasets/{TASK}/mapping.txt"
with urllib.request.urlopen(mapping_link) as f:
html = f.read().decode("utf-8").split("\n")
csvreader = csv.reader(html, delimiter="\t")
labels = [row[1] for row in csvreader if len(row) > 1]
# PT
model = AutoModelForSequenceClassification.from_pretrained(MODEL)
model.save_pretrained(MODEL)
Load the JSON file with all the comments (2500)
We load all the comments extracted from the Youtube Video and filter all the comments with more the 500 characters because the input shape of the model only supports text with less than 524 characters, you have to remember that this model was trained on millions of tweets and tweets are less than 240 characters.
# Initialize sentiment counters
positive = 0
neutral = 0
negative = 0
# Read the JSON file with the list of comments
with open("comments.json", mode="r", encoding="utf-8") as file:
list_of_comments = json.loads(file.read())
# Filter comments with more than 500 characters because the
# has a limit of 524 characters
list_of_comments = [c for c in list_of_comments if len(c) < 500]
Run the model on every comment
# Run the inference for every comment
for comment in tqdm(list_of_comments):
encoded_input = tokenizer(comment, return_tensors="pt")
output = model(**encoded_input)
scores = output[0][0].detach().numpy()
scores = softmax(scores)
ranking = np.argsort(scores)
ranking = ranking[::-1]
for i in range(scores.shape[0]):
l = labels[ranking[i]]
s = scores[ranking[i]]
if l == "positive":
positive += 1
break
if l == "neutral":
neutral += 1
break
negative += 1
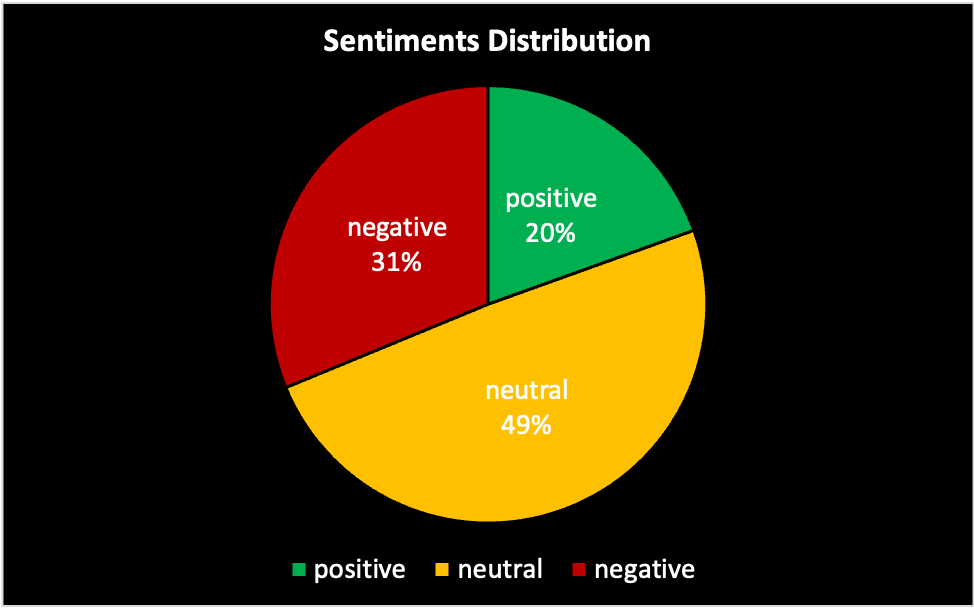
Conclusion
Looking at the sentiments distribution we can notice that there is no strong feeling from the subject of the video, Jordan Petterson talks about his difficult journey with a drug, and you can feel people are more empathetic and understanding. Most comments are inferred as being neutral, probably because most commenters talk about their own experiences with any form of an addictive drug. There are also important components to these types of videos because most of Joe Rogan’s videos are long-form interviews, which means that the comments will not focus on one subject specifically, so trying to extract any form of conclusion based on the comments will be extremely hard, so having very specific clips are better candidates for these type of analysis.
Github Repository



Youtube API
![]()